What if you're running an AI coding session and you need to either get away from computer, or you're running out of context window. You should "save the current work" somewhere, including all the conversation with the agent - the questions discussed, the options suggested, the decisions made.
So, when I had a Codex session that went over 80% of context, I tried this /handoff skill by Matt Pocock.
In Codex, I just prompted for a "handoff document" in a free form text, and Codex automatically engaged the skill.
The SKILL.md of /handoff itself is pretty simple, like most of Matt's suggested skills, here's the source:
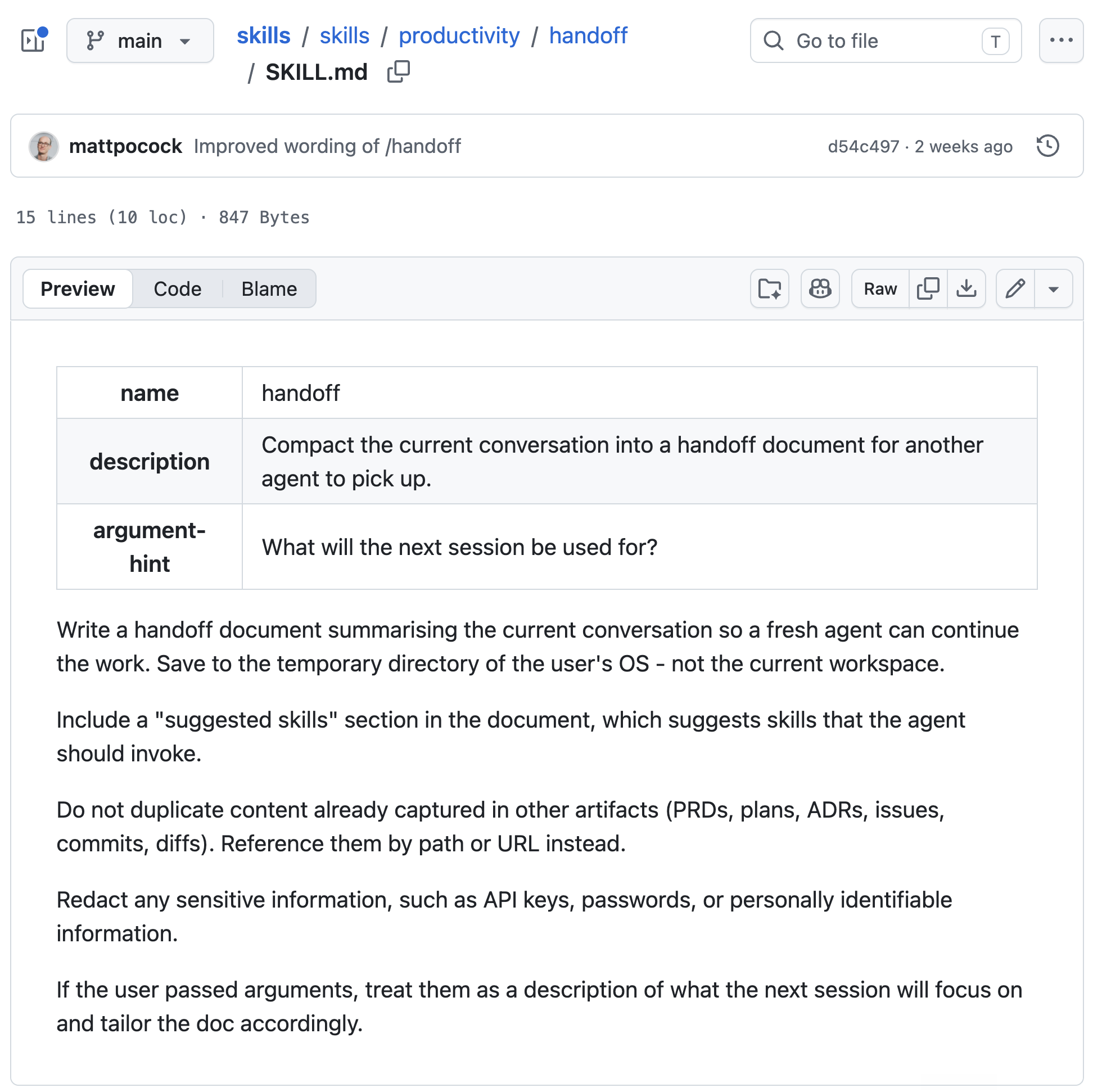
By default, the skill suggests to save the Handoff in the OS tmp directory, but I prefer such documents to be in the same project (I will not commit them to git).
So, this was the part that I overwrite with my prompt.
This was the result of the prompt, in almost 2 minutes.
And here's how that handoff.md looks like:
# Handoff: Python Eval Suite, Focus on Eval 05
## Context
Repository: `/Users/povilas/Herd/evaluations`
The user expanded an existing LLM coding-evaluation suite from Laravel/React into Python. Five Python evals were added:
- `evals/05-python-ledger`
- `evals/06-python-availability`
- `evals/07-python-markdown-tasks`
- `evals/08-python-cart-pricing`
- `evals/09-python-search-cache`
Most recent work has focused almost entirely on `05-python-ledger`.
## Current Goal
Make `05-python-ledger` a useful Python/backend-logic evaluation that is neither too easy nor too broad. The current direction is:
- Provide a mostly scaffolded Python package.
- Ask the model to implement only targeted TODO helpers.
- Still test Python engineering quality via package layout, type checking, Ruff, CLI behavior, property tests, exact money math, state handling, and business-rule edge cases.
## Important Current State
The repo now has a Python 3.14 shared virtualenv:
.venv/bin/python --version
# Python 3.14.5
Installed tooling in `.venv`:
- `pytest 9.0.3`
- `ruff 0.15.15`
- `mypy 2.1.0`
- `hypothesis 6.155.1`
`run-eval-tests.sh pytest` uses `.venv/bin/python` automatically when present.
## Eval 05 Current Shape
Template package layout:
evals/05-python-ledger/template/
AGENTS.md
CLAUDE.md
README.md
pyproject.toml
src/ledger/__init__.py
src/ledger/__main__.py
src/ledger/cli.py
src/ledger/models.py
src/ledger/pipeline.py
The template is intentionally scaffolded and should direct agents to `src/ledger/pipeline.py`.
Only these helpers are intended to be implemented by the model:
- `select_rule_category`
- `allocate_split`
- `dedupe_decision`
- `fiscal_month_for`
- `choose_bank_match`
The prompt, README, AGENTS.md, CLAUDE.md, and a comment near the top of `pipeline.py` all point to these helpers.
## Current Tests
Eval tests are in:
evals/05-python-ledger/tests/test_ledger.py
They cover:
- strict transaction CSV parsing
- exact `Decimal` money parsing
- real `datetime.date` parsing
- split parsing and allocation
- merchant rule selection priority/tie behavior
- duplicate/conflict behavior within current import and against prior state
- fiscal month grouping
- bank reconciliation with date tolerance and bank order tie-break
- deterministic JSON export
- no `float(` usage across package files
- package layout and frozen `ImportState`
- CLI via `python -m ledger import ... --json`
- Ruff and mypy gates
- Hypothesis property for split allocation preserving exact cents
## Recent Fixes and Decisions
1. The task became too broad when it asked models to build the whole ledger import system from scratch.
2. The template was refactored to provide parsing, models, import flow, JSON export, CLI wiring, and static tooling config.
3. Generated `.mypy_cache`, `.ruff_cache`, and `.hypothesis` directories were removed from the template.
4. Stale `README.md` that mentioned `src/ledger.py` was replaced.
5. `CLAUDE.md` and `AGENTS.md` were verified to have identical content.
6. Python was upgraded from system Python 3.9.6 to Homebrew Python 3.14.5 for `.venv`.
7. Prompt/template ambiguity around `fiscal_day=1` was fixed:
- `fiscal_day=1` means normal calendar months.
- For fiscal days greater than 1, dates on or after the fiscal day roll into the next month.
## Verification Commands Already Run
From `evals/05-python-ledger/template`:
../../../.venv/bin/python -m ruff check src/ledger
../../../.venv/bin/python -m mypy src/ledger
PYTHONPATH=src ../../../.venv/bin/python -m pytest --collect-only ../tests
Current scaffold passes Ruff and mypy and collects 11 tests.
The raw template intentionally fails runtime tests because the five TODO helpers raise `NotImplementedError`.
## Latest Evaluation Signal
After scaffolding, one batch had:
- 4/5 models nearly passing.
- Repeated failure was `export_report` monthly total month `2026-02` vs expected `2026-01`.
- This was diagnosed as prompt/template ambiguity around `fiscal_day=1`.
- That ambiguity has now been fixed.
Another model had an `UnboundLocalError` in `select_rule_category` from using a `candidate` variable even when a rule did not match. That is a legitimate LLM implementation bug.
The next fresh run should be judged after the `fiscal_day=1` clarification.
## Scripts and Harness Changes
Files changed earlier in the session:
- `run-eval-tests.sh`
- added `pytest` runner
- uses `.venv/bin/python -m pytest` if `.venv` exists
- `src/evals/types.ts`
- added `"python"` framework
- `src/evals/loader.ts`
- validates Python templates by `pyproject.toml`
- `.gitignore`
- ignores `.venv/`
- `open-in-ghostty.applescript`
- changed to type `cd ...` and the agent command on separate lines instead of using `&&`, because macOS keystroke handling produced `aa` instead of `&&` for one run
## Things to Watch
- If all models pass after the latest clarification, eval 05 may be too easy again.
- If all models fail, inspect whether failures cluster around hidden shape/spec assumptions before counting them as LLM failures.
- The desired band is "some fail, not all."
- Avoid adding too much new scope. Prefer adjusting the five TODO helpers or tests around them.
- Keep duplicated templates clean; do not leave cache directories in templates after running local verification.
## Suggested Next Steps
1. Run a fresh eval 05 batch:
./duplicate-template.sh 05
./open-in-ghostty.sh opencode
./run-eval-tests.sh pytest
2. Classify failures:
- Legitimate LLM errors:
- wrong rule priority/tie handling
- wrong split rounding/remainder
- wrong duplicate/conflict state logic
- wrong fiscal month after clarification
- wrong bank matching tie-break
- Ruff/mypy breakage
- CLI not wired
- Possible eval/prompt issues:
- repeated same failure across most models where prompt does not state the tested behavior
- failures caused by return shapes not described in prompt or scaffold
3. If models still spend too long bootstrapping:
- Consider adding a `TODO.md` at template root with the same five helpers.
- Consider adding `# TODO 1/5` style markers in `pipeline.py`.
- Consider adding short examples in docstrings for each TODO helper.
4. If models pass too often:
- Add one more hidden case per TODO helper rather than widening scope.
- Good additions:
- regex rule that matches normalized whitespace differently
- negative split allocation property
- conflict against prior state for changed external ID details
- bank matching with two equal date-distance candidates
## Suggested Skills
- `handoff` if this summary needs to be refreshed.
- No special skill is required for ordinary code/test edits.
- If changing Python library/tooling behavior, follow repository `AGENTS.md`: use Context7 for current docs.
## Sensitive Info
No API keys, credentials, or private secrets were involved.
Pretty impressive and useful, I will totally hand it off to the "next agent".
Though, to be honest, you could probably just prompt for a handoff document, without external skill, and AI agent would produce something similar. But Matt's skill adds a few important guidelines and guardrails of what (not) to do in that handoff.
Read more about /handoff here on Matt's blog.
